
The Group-to-Person Generalizability Problem
Reference: McManus, R. M., Young, L., & Sweetman, J. (2023). Psychology is a property of persons, not averages or distributions: Confronting the group-to-person generalizability problem in experimental psychology. Advances in Methods and Practices in Psychological Science, 6(3), 25152459231186615.
Experimental psychology is a vast and ever-growing field that the public is turning to for answers to questions that were once seen as well beyond its scope. You could say psychology is finally having its moment in the mainstream. Moral and social psychology are weighing in on how we judge what is right and wrong, how we evaluate others, and how others are most likely to act in the face of a moral dilemma. These are not minuscule claims and could have major implications on both our everyday interpersonal relationships and our society-level policies. This is because we often use experimental findings to understand people– that is, the general processes that explain human behavior. But what if we found out that most of our current methods are being interpreted in a way that means something vastly different from what the experiments actually show? This idea is what recent authors McManus and colleagues describe in what they dub the “group-to-person generalizability problem”, whereby many common methods in psychology research are only capable of explaining the effects and differences between groups of people, but are unable to conclude whether findings are due to a fundamental psychological mechanism within a single person. Why? Because scientists aren’t observing and investigating what happens in any one individual, they are analyzing differences between groups. Therefore, even if there is a statistically significant result at the group level, the majority of participants could be responding in opposition to what the group-level results would lead us to expect.
Let’s unpack that idea a bit. Take, for example, the finding in moral psychology that “people judge those who helped a stranger instead of a family member as less moral than [people] who helped a family member instead of a stranger (McManus et al, 2021).” When you read that statement, what went through your mind? Did you interpret the authors as describing what most people display? If you did, you’re not alone. After reading about either simple or complex results in a typical psychology experiment, both laypeople and scientists made the inference that the authors intended to describe the majority of participants and that support for theories in psychology ought to describe individual persons, not properties of groups. But what many current methods in psychology provide us is not an explanation of persons, but of differences between group averages. By aggregating and averaging responses across participants, we lose the nuance and information provided by the results and outcomes of specific individuals, which is in fact what we are trying to explain.
Scientists: “Recall your most recent meeting with collaborators in which you discussed hypotheses and experimental designs to test them. At any point in that meeting, did you reason about possible patterns in a way that reflected how persons may respond to different stimuli, or did you exclusively reason in a way that reflected how different stimuli would affect averages or locations of distributions?”
(McManus et al., 2021)
The group-to-person generalizability problem doesn’t occur in all psychological findings or conclusions, but is most prevalent when (1) researchers use a between-participant design, and (2) when the outcome measure is a subjective rating.
Experimental Study Design and Group versus Person Level Effects
Regarding the first point, a between-participant design compares two different groups of participants, with one group experiencing one manipulation, and the other group serving as a control or experiencing a different manipulation. Researchers then examine the differences in a specific outcome between the groups. In contrast, a within-subject design has the same participant experience all of the different manipulations, and looks for changes within the same participant – that is, each participant serves as their own “control”.
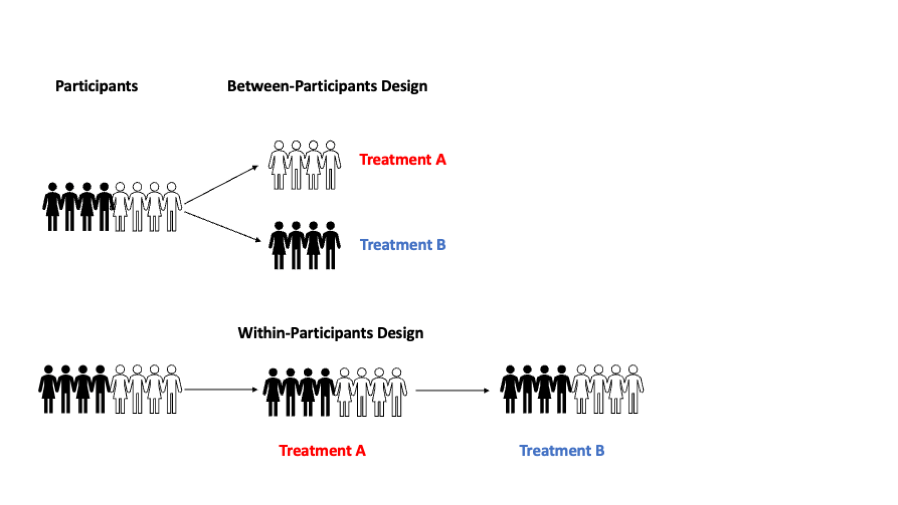
Group-level effects can be detected when observations are analyzed using statistical methods that average the responses of all the participants and compare one group to another. Individual-level effects can only be detected when we analyze the difference in response a single individual has in either condition. However, even if experiments employ within-subject designs, researchers often erroneously infer that differences found at the group level will generalize to individuals. This generalization has occurred for countless claims, which have never been evaluated at the individual level.
The authors reanalyzed the data of ten published research studies in social and moral psychology using the person-level approach – investigating the effects within one participant. They document 10 cases where this person-level approach did not match up with the major claims of the paper provided by group-level effects. In addition, in not one study did a majority of participants show the statistically significant group-level effect, and in some cases the proportion of individual participants that exemplify the major group-level claims was as low as 3%. The authors also provide evidence that group-level effects of phenomena can occur from using certain commonly used statistical tests that rely on group means (such as a t-test or Analysis of Variance), when the effect did not occur in any of the participants. That is, not a single person displayed what the authors claimed to be a generalized psychological phenomenon.
The Problem with Subjective Rating Scales
Another famous example that displays how inference errors can occur with between-participant designs and the group-to-person generalizability problem comes from an experiment by Birnbaum (1999). In Birnbaum’s experiment, two separate groups of participants were asked to make judgments using commonly used Likert scales. The participants made judgments about the largeness of specific numbers, on a 1-to-10 scale (with a rating of “1” representing a very small number, and a rating of “10” representing a very large number). One group was asked to rate the number “9”, and the other group was asked to rate the number “221”. Comparing the two groups using between-subject analysis, the researchers would conclude that people judge 9 as significantly larger than 221. But would any researcher claim this is the case? Clearly, it would be a mistake to infer so based on this study, but studies designed in this exact way are ubiquitous in social and moral psychology.
If we were making the typical group-to-person generalizability inference, what we would conclude from Birnbaum’s experiment is that based on the empirical evidence, people judge 9 as larger than 221. However, an alternative explanation is that when judging 9, people often compare 9 to other single-digit numbers, of which it is the largest, whereas, in the case of 221, people compare to other 3-digit numbers, of which 221 is rather small. The two different groups of people are not comparing 9 and 221 to each other, so we cannot make claims about whether people judge 9 as larger than 221. Because there is an objective fact about the relative largeness of the numbers, we can easily detect the generalizability error. However, in more ambiguous and subjective cases (e.g., in moral psychology), it can be harder to verify whether our inferences are false. Consider when we ask people to judge someone’s moral character, as was the case in the study that claimed people judge those who help strangers over family as more morally culpable. In this case, there is no ‘objective’ fact regarding one’s moral culpability, so noticing when we are inferring beyond the scope of the experiment’s findings is more challenging.
Looking Ahead
It is important to recognize that between-participant designs are not ‘worse’ than within-participant designs, they just have a different purpose than testing hypotheses about the psychological mechanisms of individual people. The superiority of within-subject designs lies specifically in their ability to detect psychological changes that occur within a single brain or mind, but this does not discount the numerous other goals and aims of psychological research. Not all studies attempt to identify and evaluate generalizable claims about individual psychology. Sometimes we are more interested in the efficacy of interventions or group-level differences. However, for the majority of experimental psychologists seeking to understand and explain the mind and behavior of individuals, we should be wary about generalizing group-level findings to individuals.
The author’s concern with the way current researchers draw conclusions from their data might seem like an argument about semantics or wording, but it goes much deeper and may play a pervasive role in the lack of generalizable psychological laws and theories. If most group-level effects do not bear out on an individual level, what does that mean about the entire corpus of psychological findings we currently use to explain and predict human behavior? Psychology is not only about discovering what is most likely to occur but also about mechanisms and processes that describe a majority of minds and behavior. Reckoning with this fact may require a major shift not only in the claims researchers make about their findings, but also in the way researchers communicate and interpret psychology studies at large. What does this mean for psychology lovers and readers of the field? The authors provide numerous suggestions for experimental designs and analysis to reform our practices moving forward, but in the meantime, we would be smart to not make conclusions or predictions about individuals from group-level effects!
Additional References
Birnbaum M. H. (1999). How to show that 9 > 221: Collect judgments in a between-subjects design. Psychological Methods, 4(3), 243–249.
McManus, R. M., Mason, J. E., & Young, L. (2021). Re-examining the role of family relationships in structuring perceived helping obligations, and their impact on moral evaluation. Journal of Experimental Social Psychology, 96, 104182. https://doi.org/10.1016/j.jesp.2021.104182
